Machine Learning: Building a User-Item Collaborative Filtering and Item-Item Content-Based Recommendation Systems
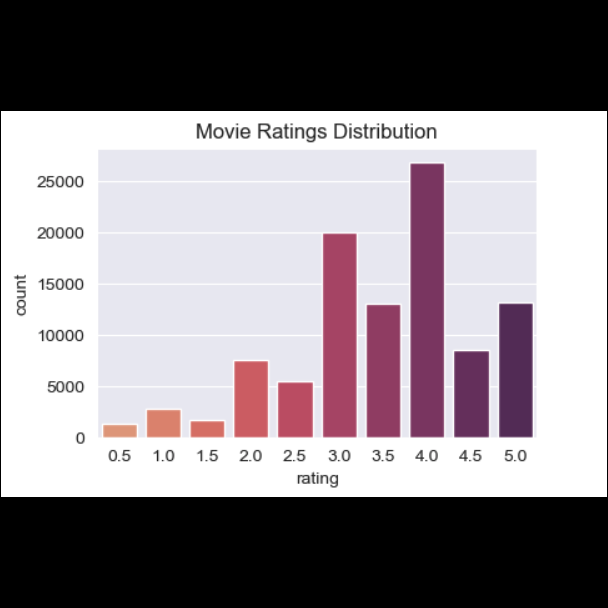
Visualizing the ratings dataset for the user-item recommender
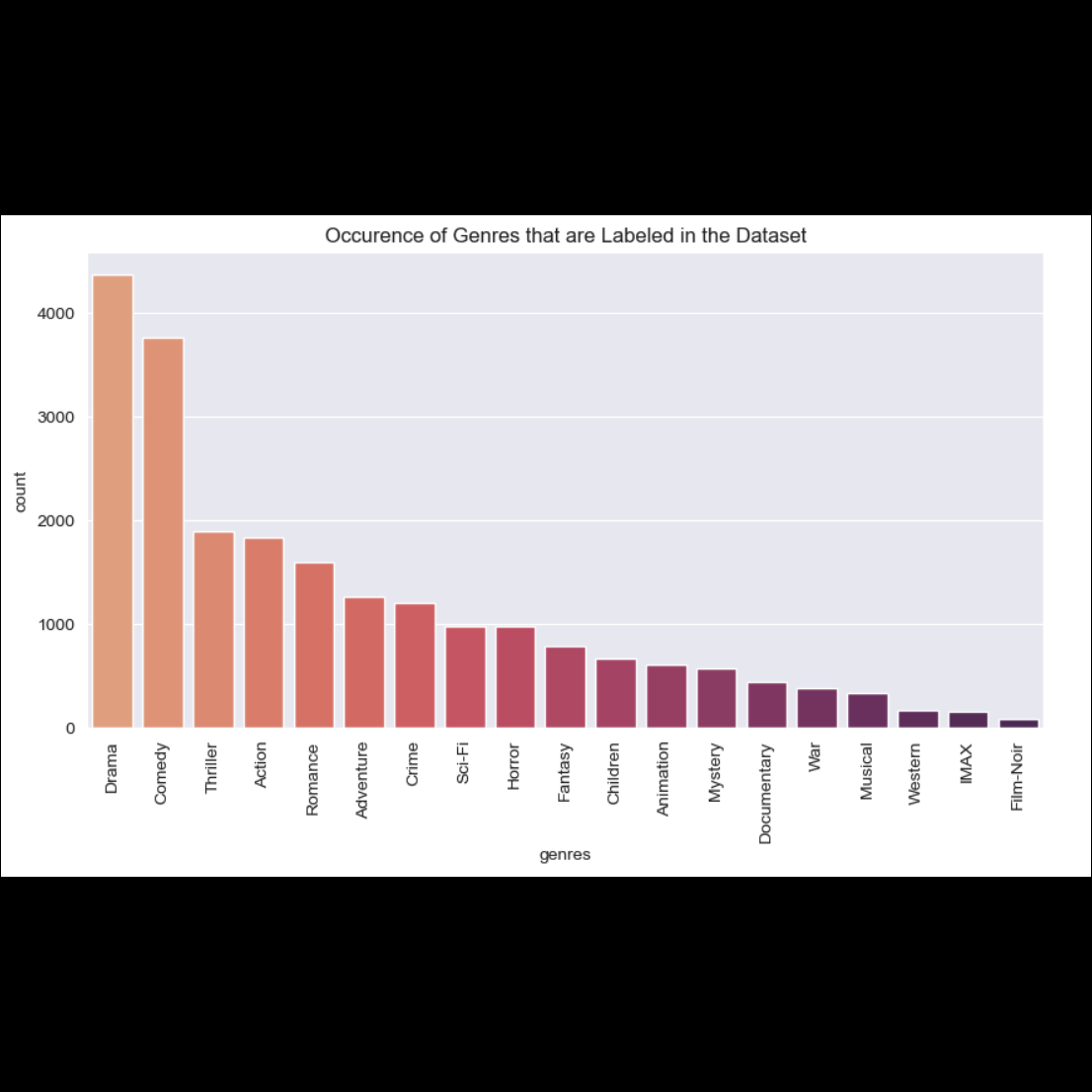
Visualizing the genres from the movies dataset
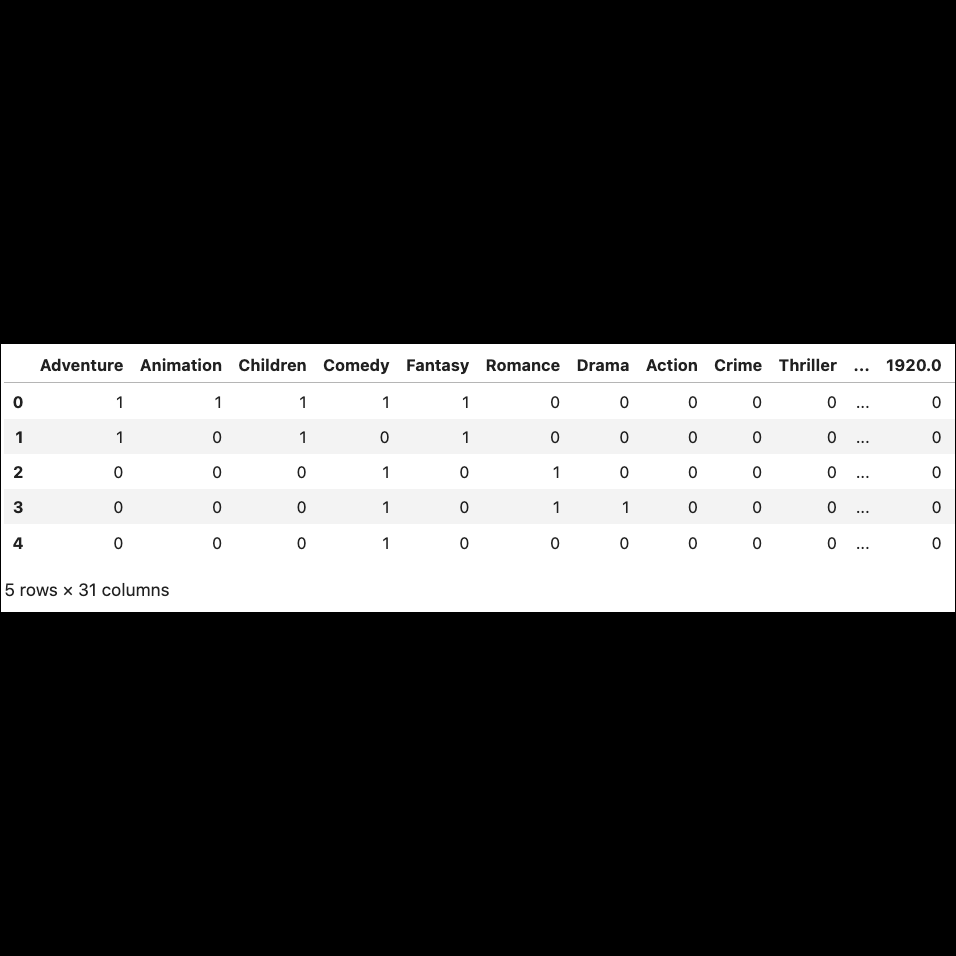
Partial view of the concatenated genres and decades dataset after one hot encoding
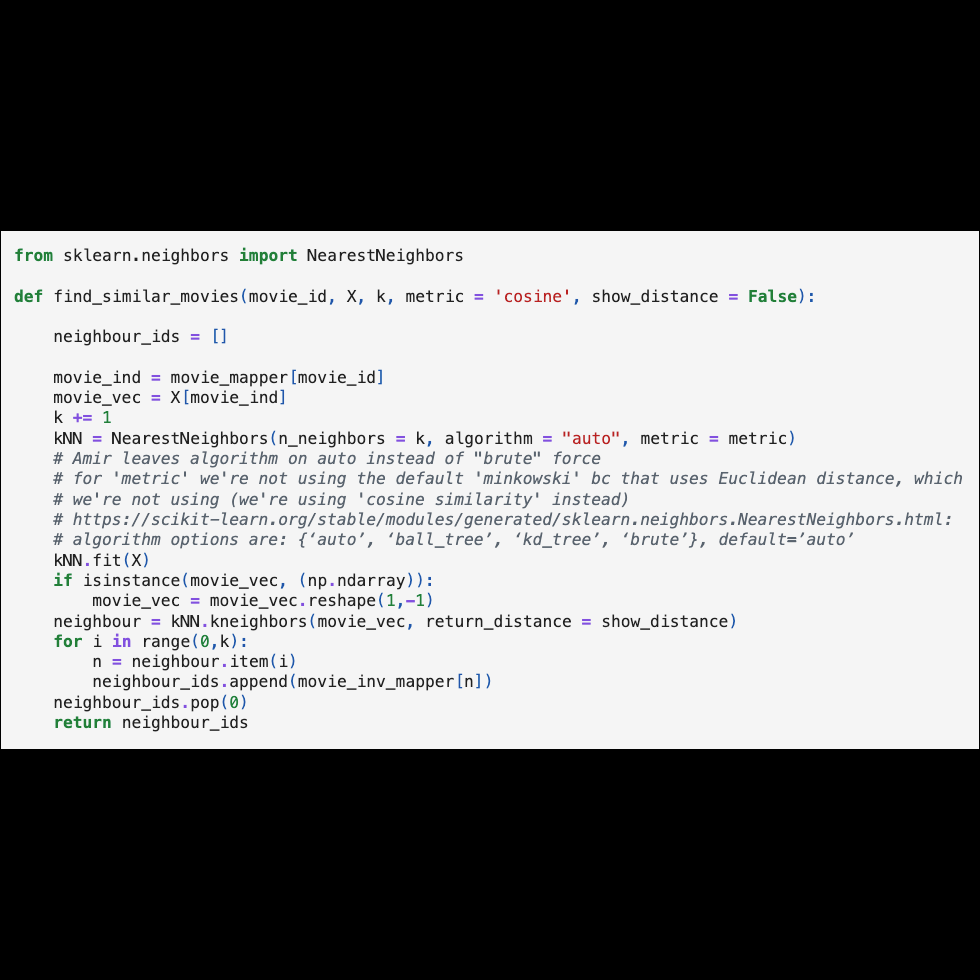
The KNN model
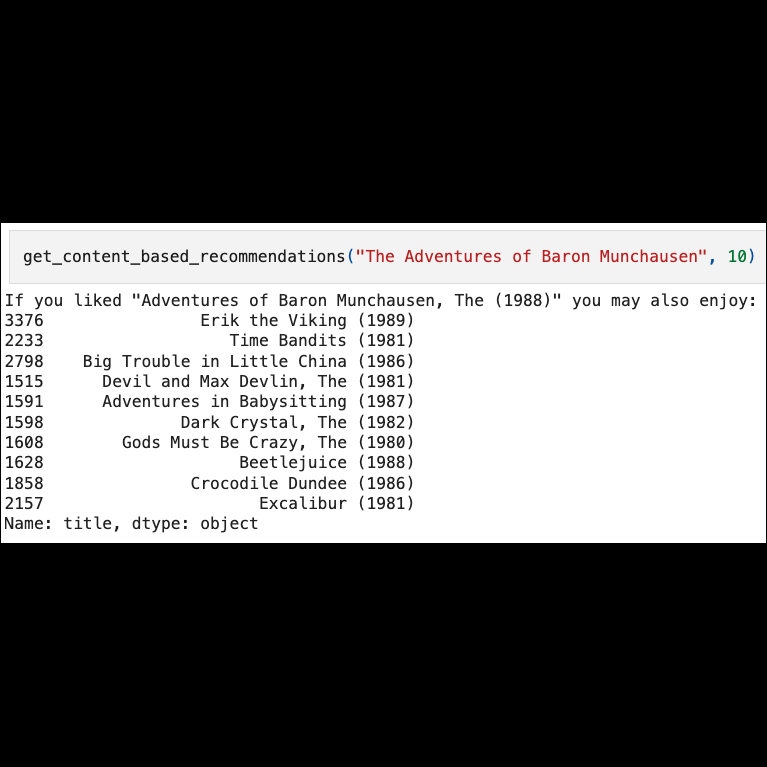
The item-item recommender based on genre and decade
(For the README file and code, please click here.)
Executive Summary
This is a replication study I did to create both a user-item collaborative filtering recommendation system and an item-item content-based recommendation system based on film data, such as ratings, genres, and years. I wanted to see how both could be built, especially because of the infamous cold-start problem that exists for new users who don't already have an interaction history.
First, to build the user-item collaborative filtering recommendation system, I downloaded MovieLens data - a ratings dataset and a movies dataset - from https://grouplens.org/datasets/movielens/. I specifically chose the dataset labeled "recommended for education and development" which has approximately 100k ratings and 9k movies by 600 users.
The ratings dataset had 100,836 ratings, 9724 unique movieIds, 610 unique users. So the average number of ratings per user was 165.3, and average number of ratings per movie was 10.37. The most commonly given rating was 4.0.
On its face, the movie "Gypsy" (1962), a musical, had the lowest rating with just one rating of 0.5 - while "Lamerica" (1994), an adventure/drama, had the highest rating of 5.0 given by 2 users. But since a recommender system isn’t supposed to just rely on a sorting of ratings from highest to lowest or vice versa, this is where the Bayesian Average - or a weighted average - was utilized to find more meaningful results. So by incorporating Bayesian averages, the best-rated films were actually "The Shawshank Redemption," "The Godfather," and "Fight Club" - while the worst were "Speed 2: Cruise Control," "Battlefield Earth," and "Godzilla," according to these users.
Then, in order to carry out collaborative filtering and create the actual movie recommender, we had to transform our data into a user-item matrix - with rows representing users and columns representing items.
We then checked the sparsity of our matrix by dividing the number of non-zero elements by the total number of elements, which turned out to be 1.7%, meaning that 1.7% of the cells are populated with ratings. (The general rule of thumb is that the matrix sparsity should be not be lower than 0.5% to generate reliable results. So we were okay.)
Then, we built our K-Nearest Neighbors model using sklearn. Our model find_similar_movies() worked by taking in a movieId and user-item matrix (X) and outputting a list of movies (k) similar to the movieId of interest. And we also created another mapper that maps movieId to title so that the results could be interpreted.
Of course, for this to work, you had to refer to the movies.csv file attached, and look up a film's movieId in order to input it.
***
Then, we built the content-based recommendation system, which, as mentioned earlier, is particularly useful for addressing the cold-start problem, a notorious problem associated with collaborative filtering. This issue arises when new users or items lack sufficient interaction data, making it difficult for collaborative models to generate recommendations. Content-based filtering helps overcome this by relying on item and user features rather than past interactions.
We performed feature engineering by extracting the release year from the movie titles and grouping the years into decades. We also extracted the individual genres listed for each film. Additionally, we removed films that were missing a release year—only 24 out of 9,742 entries were affected.
To build our content-based recommendation system, we first restructured the dataset so that each row represents a movie and each column represents a feature (genre or decade). For the "genres" column, we applied one-hot encoding to represent each genre as a binary feature - with "1" indicating the movie belonged to that genre and "0" meaning it didn't.
Next, we transformed the "decade" column using one-hot encoding, creating a separate column for each decade. We then combined the genre and decade features by concatenating them into a single feature matrix. With all features consolidated into one dataframe, we were ready to build our content-based recommender.
For our similarity distance measure, we used cosine similarity rather than other options - https://dataaspirant.com/five-most-popular-similarity-measures-implementation-in-python/ - since it measures the orientation (direction) of the vectors rather than their magnitude.
To generate relevant recommendations based on a movie title input — such as "GoldenEye" — we first needed to find its corresponding index in the cosine similarity matrix. For this, we created a movie index mapper that maps movie titles to their matrix indices. Once we had the recommended movie indices (the top 10 similar movies), we could retrieve their titles either by creating an inverse index mapper or by using .iloc on the title column of the movies dataframe:
So if you enjoyed “goldeneye (1995)” you might also like:
84 Broken Arrow (1996)
378 Cliffhanger (1993)
431 Executive Decision (1996)
479 Surviving the Game (1994)
592 Rock, The (1996)
648 Chain Reaction (1996)
754 Maximum Risk (1996)
1053 Die Hard 2 (1990)
1145 Anaconda (1997)
1171 Con Air (1997)
Tool Used
Python in a Jupyter Notebook via Visual Studio Code